January 30, 2021
Apache Kafka Connect Usage Patterns
Kafka Connect is a tool for streaming data between Apache Kafka and other systems like Oracle, DB2, JMS, Elasticsearch, MongoDB, etc. Teams can configure connectors that move large collections of data in and out of Kafka. As Kafka Connect user you don’t have to write any piece of software when there is an existing connector implementation for your system. Depending on your load profile you can run multiple Connect workers which build an Connect cluster.
I had recently an interesting discussion how teams can or should use Apache Kafka Connect. We came up with two usage patterns for Apache Kafka Connect:
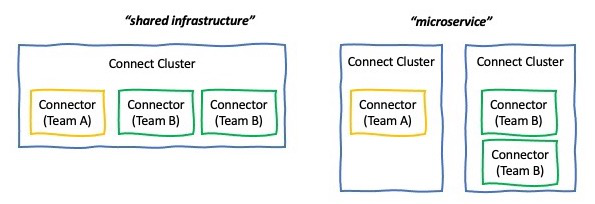
- Shared infrastructure - All teams share the same Kafka Connect cluster.
- “Microservice” or shared-nothing architecture - Every team has their own Kafka Connect cluster.
Note: I assume that you will run Apache Kafka Connect in distributed mode. This provides scalability and automatic fault tolerance for Kafka Connect.
Shared Infrastructure Usage Pattern
In this usage pattern the Kafka Connect cluster is shared between multiple teams and the platform team is responsible to run the cluster. This means that the resources (memory, logs, configurations, etc.) and runtime (JAR’s) are shared between different teams.
When you use the shared infrastructure usage pattern you have to consider the following topics:
Responsibilities:
- Who gets notified when a connector is failing?
- Who is responsible in fixing connector failures?
- How to distinguish between infrastructure problems (memory, connectivity, etc.) and connector problems (schema / data mismatch, configuration errors, etc.)?
Boundaries / Isolation:
- How do you enforce authentication, authorization and role-based access control?
- How to ensure that teams can only deploy or modify their own connectors?
- How to secure the access to sensitive configuration settings like credentials?
Coordination:
- How to do you coordinate patches or rollouts of new versions with all the teams?
- Can a team stop the rollout when there are some breaking changes?
“Microservice” or Shared-nothing Architecture Usage Pattern
In this usage pattern the platform team provides the right tools for the teams to to deploy and run a Kafka Connect cluster. Here we have clear boundaries between the teams and clear responsibilities.
With the microservice usage pattern you have to to consider the following topics:
Operational overhead:
- Can you live with the operational overhead when every team runs their own Kafka Connect cluster?
- Should you organize cluster also by domain or functionality?
Skill / Tools:
- Does your teams have the right skills to run and operate Kafka Connect?
- What are the right tools to facilitate the daily life with Kafka Connect?
- How to automate rollouts and updates?
Conclusion
Shared Infrastructure has the advantages that the team does not have to care how to operate and run Kafka Connect. The biggest issue is that all teams share the same runtime and resources. This increases the complexity regarding security and responsibilities between the teams.
With the microservice usage patterns it’s clear who is responsible and to blame when a error occurs (You build it, you run it!). The main concerns are that your team needs the right skills to run Kafka Connect and the operational overhead when every team runs their own Kafka Connect cluster.
We started with the shared infrastructure usage pattern and ended up with the microservice usage pattern. You should not underestimate the effort in provide the right tools and teach teams how they can run and operate Kafka Connect by themself.